
Data Layouts: Where Bytes Find Their Forever Home
How Vortex tackles data layout challenges across analytics and machine learning workflows


If you’re anything like me, you read every new message on dev@apache.parquet.org with the hope of learning something new about how to store and compress data. We often take file formats like Apache Parquet for granted. However, these pieces of software are built upon years of research and foundations laid out decades ago. The data processing landscape has changed significantly since then. As we build Vortex, a next-generation columnar file format, it’s worthwhile to revisit the history that brought us here and question whether the assumptions of the past still hold true.
The Evolution of Database Storage Models
In the early days of databases, the predominant method was to store records sequentially (row-wise), with record offsets stored at the end (NSM - N-ary Storage Model). This row-wise model underpins many common file formats, such as CSV and Apache Avro. The alternative approach of splitting data into individual columns (DSM - Decomposition Storage Model) was rarely adopted, as the limitations of storage and compute hardware at the time often led to significantly poorer performance in practice. The first significant breakthrough in performance came with PAX[1] (Partition Attributes Across), which blended the strengths of both models by storing individual columns within row partitions. Later research confirmed what we now consider commonplace: that columnar storage with SIMD-accelerated execution on the DSM model could deliver substantially better performance[2]. However, the story is more complex. Storage models were heavily influenced by the technological constraints of their era. When NSM was introduced, most data processing time was consumed by fetching data from external storage. Since then, storage devices have come much closer to CPU performance, and CPU development has shifted from boosting single-core speeds to increasing core counts. Today, nearly all file formats designed for analytical use cases—such as Apache Parquet and Apache ORC—follow the PAX design pattern.
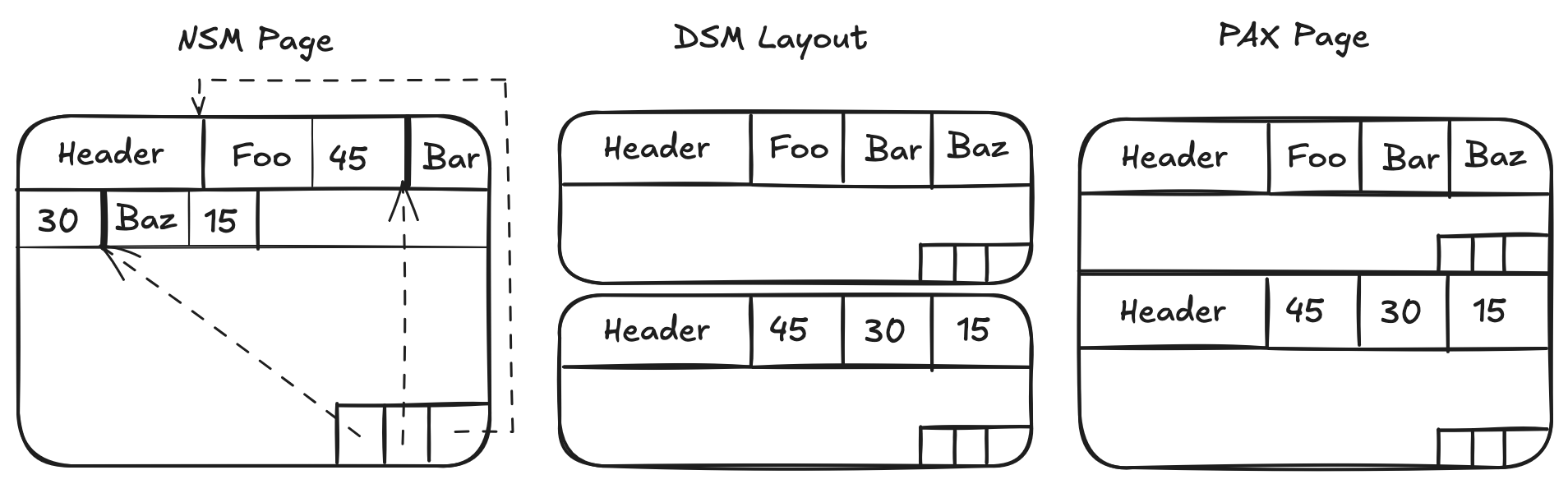
The migration of data from traditional databases to cloud platforms, with their virtually limitless storage capacity and significantly higher access latencies, has forced us to revisit the evolution of database systems. The inherent separation of storage and compute in cloud infrastructure allows us to re-examine prior designs and potentially improve upon existing solutions.
[1] https://www.vldb.org/conf/2001/P169.pdf
[2] https://ir.cwi.nl/pub/13807/13807B.pdf
Analytics is all about columnar access
Both Apache Parquet and Apache ORC are columnar file formats that utilize a PAX-style layout. Parquet for example, calls their PAX page a "row group", each of which contains values for all columns, one after another, for a single set of rows.

While row groups maintain reasonable locality for entire rows, they also allow access to batches of values within specific columns. However, this reliance on locality introduces significant challenges when dealing with a large number of columns, or columns of varying widths.
The greater the disparity in size between columns, the more pronounced the issues become, making it difficult to balance file organization and query performance. This forces a trade-off: either include a reasonable number of rows, which can result in excessively large row groups, or keep row group sizes manageable, but with too few rows for efficient scanning.
Given these constraints, the design of Parquet (and any purely PAX-based format) has no obviously good solution. Your storage system will live with tradeoffs, leading to endless frustrations.
When fast record access matters
Analytical workloads have increasingly adopted PAX-like file formats to maximize performance. However, this optimization hinges on a key assumption: that the underlying data evolves slowly or remains largely static (which, incidentally, is where Apache Iceberg gets its name from). PAX-like formats, due to their structure, struggle with high-frequency writes. This creates a situation similar to the skewed row groups problem—we end up with many small files that hurt write performance. That’s the trade-off you accept when adopting a PAX-like solution. After data arrives, you must perform compaction (combining smaller files into fewer, larger files optimized for your system). The constraints of these file formats are such that the simplest solution is to introduce another file format that supports fast row access and appends. In this new format, you buffer recent, un-compacted, writes and ensure readers know how to intersperse them with existing records until compaction occurs. This technique is employed by most systems built on top of Parquet, such as Apache Iceberg or Databricks Delta Lake.
Beyond high-frequency writes, there’s an entire world of data storage systems that still prefer row-based access. For instance, the TensorFlow project introduced TFRecord to address the needs of machine learning workflows. TFRecord is a row-oriented format, making it particularly suitable for training tasks where accessing an entire row at once—such as data, labels, embeddings, and metadata—is essential for updating model state or evaluating records.
TFRecord relies on Protocol Buffers (protobuf) as its definition language, a format that has gained widespread popularity for data interchange. That said, if you attempt to use TFRecord for analytical tasks, its performance would fall short compared to specialized formats like Apache Parquet. As a result, if your data is used beyond machine learning, you’re likely to maintain two separate copies: one in TFRecord for training and another in Parquet for analytics.
A little bit of framing
In an era dominated by remote object stores, many traditional file formats are no longer aligned with optimal access patterns. Numerous image formats, for example, rely on a series of small initial reads to decode metadata, followed by larger reads for raw data. However, these small reads become highly inefficient when working with object stores, where such operations are costly both in terms of price and performance. The performance cost is especially significant, as object store connection latency can range between 20-100ms, which is much higher than the ~100μs latency measured on a local SSD.
Cost-wise, you end up paying for every request made to the object store, regardless of the amount of data transferred. Despite each request being extremely cheap—around ~$0.40 per 1 million requests—this cost can quickly become a dominating factor for large datasets that are frequently accessed.
While default file format readers can still function by treating object stores as a filesystem facade, this approach is far from ideal for data retrieval. All of these issues make it an obvious choice to redesign the format in which data is stored, rather than optimizing every access pattern.
One such specialized format designed for large collections in object stores is WebDataset. The idea behind it is to frame (wrap) images along with their metadata into a tar archive. These archives can be randomly accessed if necessary—for example, you can quickly jump to the offset for a given file. More importantly, they can be efficiently streamed, as you retrieve one large file with a single request, thereby leveraging the performance of sequential reads on object stores.

Vortex
The variety of storage paradigms showcased by the file formats discussed in this post highlights that no single data layout is universally superior. There is a clear opportunity to offer analytics users an easier to manage format, while machine learning users could benefit significantly from being able to use analytics datasets directly in their projects without preprocessing or maintaining duplicate copies.
Our key takeaway from these examples is that it’s unwise to enforce a rigid, one-size-fits-all data layout. The differing access patterns between analytical workloads, value retrieval, and machine learning demand flexibility in how data is organized. Modern data formats are increasingly blending partial normalization with PAX-like partitioning to strike a balance between locality, compression efficiency, and sequential access performance.
Vortex design aims to leverage the historical lessons in file design while allowing for experimentation with data layout. Recognizing the need for customizable layouts, we created a self-describing format capable of serving multiple use cases while offering consistent management and a user-friendly interface for integration. Users can prioritize record access, storage efficiency, or scan performance, depending on their needs. By simplifying experimentation, Vortex aims to unlock research into performance improvements that were previously out of reach due to the complexity of developing a file format from the ground up. While the most common approaches for analytical workflows involve splitting data column-wise or row-wise, Vortex allows for entirely different chunking strategies tailored to specific columns or even extracting shared data across multiple chunks or columns. This pluggable behavior ensures that new strategies can be added in the future as we gain deeper insights into access patterns.
At its core, Vortex layout tree defines how the data is divided and how to reassemble it into a batch of data. The layout also specifies which parts can be pruned or loaded lazily during file reads. Stay tuned for future posts, where we’ll explore in detail how Vortex interprets these layouts and handles data reading with pushdown optimizations.



