
Trick-or-treating with Vortex
On a journey to make your data more fun sized


Here at Spiral, we’re building the data warehouse for the age of AI. We’ve been hard at work on Vortex, our joint file-memory format for wrangling large arrays. Building a new analytic file format is no small task, and our team has been hard at work across the board, from compression codecs and performance tuning all the way to improvements in the Python SDK and documentation.
With the spirit of Halloween in the air, we wanted to take a moment to reflect on all the progress we've made this month.
Treat 🍫: German Strings

In #1082, we introduced a new canonical string format for Vortex: the variable-length binary view, which we affectionately call the VarBinView.
If you’ve watched an Andy Pavlo lecture or keep up with database lore, you might have also heard these referred to as “German Strings”, so named because they were introduced by the folks at TUM in their paper describing the Umbra database. Much has been written about the benefits of German Strings for query processing, and we encourage you to checkout recent articles by the folks over at InfluxData as well as Polars.
It’s been just over a year since Apache Arrow added an array type to represent German Strings (which arrow-rs calls StringView ). We added support to Vortex shortly afterward, however due to missing support in Apache DataFusion and PyArrow, we were unable to make it our default Arrow-compatible encoding for strings. Over the course of this year however, the DataFusion contributors have done tremendous work to improve support for StringViews. We were also glad to do our part, contributing bug-fixes and performance improvements like #6077, #6168, #6171 and #6368. It was a glorious day when we managed to get all TPC-H and PyVortex tests running with VarBinView 🎉
It’s still early days, but now Vortex users that need to share data via Arrow can do so using the very best string format around.
Trick 👻: Filtering compressed strings in-place
In our benchmarks, we've found that our statistics-based compressor will pick FSST to compress most string datasets. It’s fast and effective, and this month we landed a change to make it even better.
FSST uses a symbol table for compression and decompression. Given the same symbol table, the same string will compress into the same binary code sequence deterministically. As part of #1082, we changed the evaluation logic of = or != predicates over FSST-encoded arrays. Previously, we would decompress into an Arrow string array and evaluating using Arrow compute kernels. We now compress the comparison value using the symbol table, and execute the operation over the compressed array.
This cut the latency of certain TPC-H queries in half, purely by avoiding the need to decompress.
Treat 🍫: ALP-RD for high-precision float data
Floating-point numbers can encode up to 64 bits of precision. However, many real-world datasets use only a fraction of that range. Stock prices, temperature measurements and wind speeds are all relatively low-precision, and with some cleverness you can reclaim some of those bits.
The Adaptive Lossless floating-Point algorithm (“ALP” for short) allows Vortex to store low-precision floating point numbers as small integers, which we can then encode using one of several lightweight integer encodings such as frame-of-reference and bit-packing. We implemented ALP support way back in #72, and it’s served us these past several months as our only floating point compression codec.
However, sometimes you do encounter a dataset that calls for high precision, whether it’s geospatial coordinates or high-energy physics.
This month, landing in #947 we implemented the “ALP for real doubles” extension, also known as ALP-RD. This variant exploits the fact that vectors of high-precision numbers often share the same exponent and initial bits of precision, allowing us to identify a good cut point to divide all of the vectors into left and right halves. We can pack the right-bits down from 64 to whatever the cut-point dictates, while the left bits can first be dictionary-encoded, and then bit-packed.
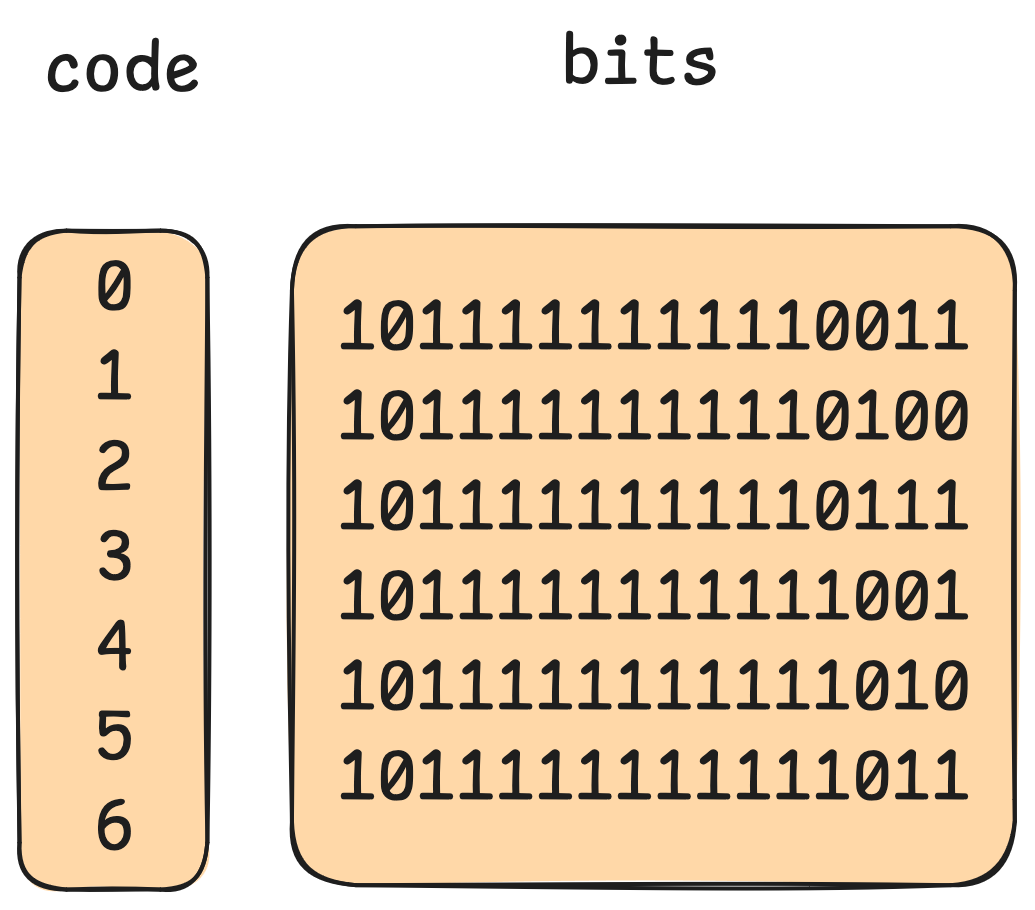
As an example, say we take an array of longitudes for 10 American cities:

Look closely at the binary: can you see it? It’s clear that the left-most bits for the values tend to look the same, while the right-most bits seem fairly random. If we choose a good split point, we can deduplicate some of this recurring information.
Let’s take bits 0-15 to be the left, and bits 16-63 as the right:

There are 6 unique values on the left, which we can assign as dictionary codes 0 through 5.
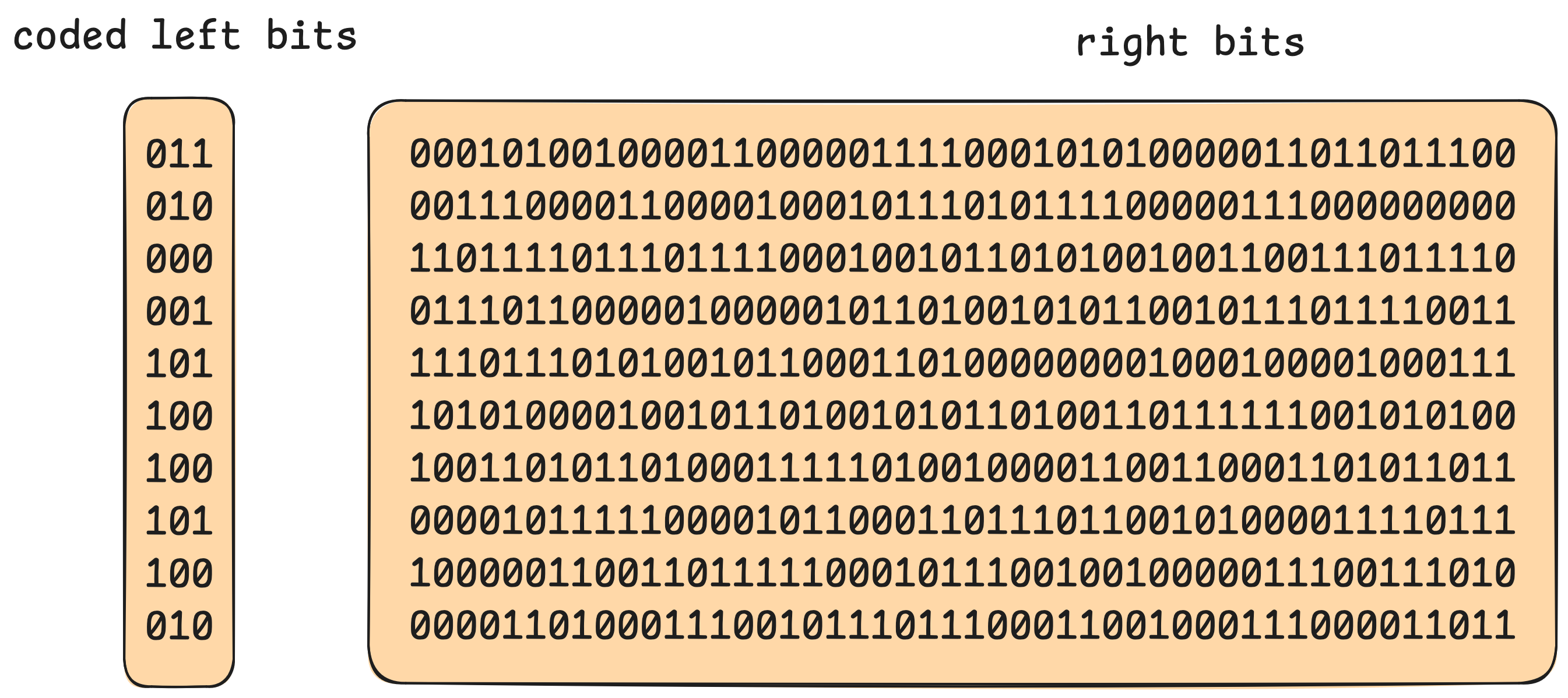
Bit-packing the left and right halves individually, we can represent this in 48 + 3 = 51 bits per value versus the original 64, a savings of over 20%, without any loss of precision! There are some other tricks that we won’t cover in this post, but we encourage as always to check out the code, open issues, and ask questions!
Similar to FastLanes and FSST, we’re working to move the core logic behind both ALP and ALP-RD out into their own Rust crate to be easily accessible to the broader community, so stay tuned for updates on that front.
Treat 🍫: File format improvements
The file format has grown up a lot this month, and a big focus has been on adding the necessary infrastructure to allow backwards-compatible changes moving forward.
In #1077 we added version information to our file footers, setting the stage for version-aware readers in the future. And with #1098, we’ve added a new self-describing layout definition with the schema provided inline with the array data. This is important for layouts with optional fields that have to be discovered at runtime. Internally, we’re keen to use this to represent column chunk statistics, where all statistics fields are optional and the set of statistics changes over time.
Separately from versioning support, the other big change for the format is an initial implementation of filter pushdown. This is a critical component of any analytic file format, allowing us to skip both scanning and decoding of file sections that will not be used.
As a side effect of this change we no longer force arbitrary partitioning on read but instead the natural partitioning as defined by the file. We avoid needlessly slicing and recombining data which leads to full scan improvements.
We’re excited to continue extending this work, with further improvements like statistics pruning, index selection and parallel reads coming soon.
While we anticipate a few more breaking changes to the format (we need to finish auditing the encoding-specific metadata) we are laying the groundwork to get to a stable future.
Trick 👻: Compressor performance tuning
When writing a Vortex file, the most expensive part (by far) is compression. We made major improvements in the Compressor this month, which led to much faster writes, smaller files, and faster reads!
- We improved the objective function in the sampling compressor, resulting in up to 30% faster compression and up to 70% faster decompression. The key insight here was to add a fixed 64-byte penalty to each array child in estimating size, which helps us avoid choosing a deeper compression tree (more expensive to decompress) to save e.g., 1 byte overall.
- We changed the compression strategy for chunked arrays, improving compression throughput by up to 50%. For chunked arrays, rather than “starting over” on each chunk when searching for a good combination of encodings, we now check if the previous chunk’s chosen encodings perform well on the new chunk. If they do, then we simply reuse the same set of encodings.
Treat 🍫: An improved Python integration
The Vortex Python API has also made significant strides this month. PR #1042 enabled Vortex to create Pandas data frames without copying data, leveraging Pandas' support for Arrow extension arrays and data types. Shortly after, PR #1089 brought the PyArrow Dataset API to Vortex files.
The Dataset API serves as a bridge between query engines (like DuckDB and Polars) and file formats (such as Vortex or Parquet). It allows query engines to "push down" column projections and row filters directly into the file format. For columnar formats like Vortex, this means reading fewer columns translates to reading proportionally fewer bytes. In workloads constrained by bandwidth or decoding time, this efficiency boost frees up more processing power for meaningful analytical tasks.
We're also excited to publish our new Documentation!
Treat 🍫: Community contributions
Finally, we also wanted to acknowledge external contributions that we accepted this month. We’re excited to see people in the broader data community take interest and we look forward to more PRs!
- 35% faster decompression with less boundary check (FSST) by @XiangpengHao (first contribution! 🎉)
- feat: add dbtext decompression benchmark (FSST) by @NickCondron (first contribution! 🎉)
- Implement a filter compute kernel for dictionaries that avoids eager decompression, also by @XiangpengHao
For what good is a bag of treats if you can't share it with friends?
Happy Halloween!



